

On AI Doom
Are the doomers right about takeover risk?


Last month, someone tried to kill OpenAI CEO Sam Altman.
It was a pretty feeble attempt – a single Molotov cocktail, which made it no further than a driveway gate – but the letter the perpetrator carried with him left no doubt as to his intentions.
Nor to his rationale. In other documents carried on his person, Daniel Moreno-Gama outlined his belief that the frontier AI companies are currently driving humanity towards a near-certain extinction at the hands of rogue AI. He even wrote a Substack post on the matter a couple of months prior, as well as a “Eulogy for Man” (be prepared to lose a few brain cells).
Unfortunately, while his actions were extreme, his beliefs are not that far out of whack with many of the leading voices in the field:
Sam Altman himself said in 2015, “AI will probably lead to the end of the world, but in the meantime, there'll be great companies”
Anthropic’s founder & CEO, Dario Amodei, calls himself an optimist for believing the probability of a “really, really bad outcome” is only 25%
Elon Musk puts the likelihood of human extinction from AI at 20%
Geoffrey Hinton, “godfather of AI” and the second-most cited living scientist, personally puts it at 50%
The median AI researcher now puts it above 10% (and rising)
Public concern is starting to catch up, though surveys still indicate most people are more worried about AI’s threat to the economy or the citizenry’s cognitive ability than existential risk. My impression from conversations with friends and strangers is that we’re in a strange in-between phase, where people are increasingly aware of the potential threat, but not emotionally affected by it.
I do not think this will remain so for long. Fear is perhaps the strongest force in the human psyche – and, alongside anger, the easiest for the media to inflame. A year from now, should rapid AI progress continue, I expect AI extinction risk will be one of the top political issues on the public’s mind, especially with people like Bernie Sanders already pushing it. When this happens, I imagine the public discourse will likely collapse into identity politics – safety advocates on the left, anti-regulation free market people on the right – with little nuance or independent thought.
So before that, it’s worth taking an honest, sober look at the arguments of those who are convinced rogue AI will kill us all. I’ve spent much of the last couple of weeks studying their world – reading their holy texts, watching their debates, weighing their arguments. To my surprise, I found far more intelligent, nuanced discussions than I’m used to seeing on the internet, amongst a group of people who have been disconcertingly right so far. And today, I want to discuss what I’ve found – what these people get right, what I think they get wrong, and ultimately, how scared we should be of an AI takeover, as frontier models continue their incessant march in capabilities.
Contents
Against “Nothing Ever Happens”
Are we about to build Superhuman AI?
The Bear Case on AGI
The Bull Case
AGI vs ASI
The Case for Existential Risk
Rationalism and Eliezer Yudkowsky
If Anyone Builds It, Everyone Dies
Discussion
Against IABIED
Everybody Might Still Die
Other Forms of Existential Risk
Gradual disempowerment
Misuse
What should we do about it?
Final Thoughts
Against “Nothing ever happens”
At the risk of repeating my last post – there is an unavoidable natural instinct, upon hearing the suggestion that AI could wipe out humanity, to deem it outlandish – it just seems instinctively so far-fetched, regardless of the arguments for and against. I mean, try to picture it – ten years from now, and everyone’s just dead, and a bunch of bastard robots are running everything? No, don’t be silly.
The simulation heuristic is a mental shortcut, whereby we judge the probability of events based not on a sober assessment of the facts, but based on how easy it is to imagine something. Like most heuristics, it serves us well the vast majority of the time. But not always…
The year is 2019. Transmissible disease experts have been warning for decades that the world is woefully unprepared for a pandemic – something they argue really isn’t that unlikely. The US, ranked first in the world in pandemic preparedness, has just 12 million usable N95 masks in stock, against an estimated national need of 3.5 billion in a respiratory outbreak. The shortfall would cost maybe two billion dollars to make up – roughly the same as a B2 bomber, or a tenth of the TSA budget. But no politician alive has lived through a serious, fast-spreading pandemic – and neither have the folks at the Strategic National Stockpile. And so, they ask for only $1 billion, mostly for anthrax and smallpox vaccines (the SNS director still remembers the anthrax attacks that killed 5 people in the wake of 9/11 – he has no trouble simulating that).
Congress grants them $700m.
The date is February 26th, 2020. 47 countries have recorded cases of the novel coronavirus. Early estimates suggest each infected person infects 2-3 others, mostly before they even notice symptoms. Cases and hospitalisations are doubling every three days in the US. The arithmetic is unambiguous – absent a major intervention, the majority of the US population will be infected in a matter of months.
In a televised address, the WHO Director-General notes that outside China, there are less than 3,000 cases in a population of 6.3 billion. He does not mention the rate of change. He denies that it should be considered a pandemic. Such a label would add “unjustified fear and stigma”, he says.
Two months later, half of the global population are under stay-at-home orders and over 200,000 people are dead.
Covid is not an anomalous example. This story plays out over and over again through history – humans fail to adequately prepare for an impending threat, however strong the reasoning behind it, because it’s hard to imagine or lacks precedent. This must be avoided.
There is a better-defined dismissal that I often see, which is that people have always worried about some new technology bringing the end of the world, and things have always chugged on regardless. This is not without merit – if every generation for time immemorial had thought they saw armageddon on the horizon, and had a pretty well-reasoned argument as to why, it would be quite rational to largely disregard the current generation’s fears, even if they sounded quite reasonable, and put it down to this being something humans just do – a manifestation of our natural fear of change. As Thomas Macaulay said, in reference to fears about society’s decline – “But so said all who came before us, and with just as much apparent reason.”
But… is it true, in terms of existential fears? Let’s check the record.
As far as I can tell, scientifically-serious concerns about the end of the human race began with the invention of nuclear weapons. Nukes enjoyed two rounds of existential risk fears. In the first instance, Manhattan Project scientists worried that the heat generated in a detonation might be so intense as to cause a fusion chain reaction in the atmosphere. However, they then calculated this would not happen and mostly stopped worrying about it. The second round of course came during the cold war, once both sides had stockpiled enough nukes to conceivably make Earth uninhabitable. Nowadays, we’re fairly sure we don’t have enough to fully wipe ourselves out (cucarachas that we are) – but it’s pretty widely understood that an all-out nuclear war would be a rough day.
What else? In the 70s, scientists got pretty worried about recombinant DNA, leading to a self-imposed moratorium in 1974. But this was not really an extinction-level worry, and by 1975 the scientific community had agreed to lift the moratorium in favour of an agreed set of containment and risk management measures. The world generally remembers this as a showcase of good practice – caution in the face of unknown risks, international discussion and collaboration, reassessment upon the receipt of evidence indicating risks were on the lower end. Not really a cautionary tale of the perils of listening to doomsayers.
Y2K is a more classic example of societal collapse fears – sensationalistic media coverage and a series of books with names like Time Bomb 2000, The Millennium Meltdown, and The Millennium Bug: How to Survive the Coming Chaos stirred the public into a panic in the late 90s. After the millennium turned with barely a hitch, much of the public came to believe Y2K was essentially a hoax. In truth, while the risks were certainly overblown, it’s estimated $300-600bn had to be spent on remediation, and many systems would indeed otherwise have failed.
Then in the 2000s, there were the Large Hadron Collider black hole fears (and RHIC before it), if you recall – which saw people calling CERN in tears begging them not to switch it on, scientists receiving death threats and so on. But this was never really a matter of serious concern to the experts, more an unfounded public hysteria.
Arguably global warming fits the bill better. “Climate doomers”, who believe warming-driven extinction to be inevitable, do indeed exist. But the experts do not agree with them – while the impacts may be pretty bad if some of the feared feedback mechanisms take effect, worries of cascading tipping points turning Earth into Venus are basically unmerited.
So… the only thing from history that really seems to match the protracted existential fear around AI, including from experts, is nuclear weapons. That does not to me seem a historical precedent in favour of “Ah, don’t worry about it, these things always sort themselves out.” It is true that nuclear weapons have not ended the world, but this has not been just the natural way of things – we have the massive diplomatic effort of nuclear non-proliferation to thank. A lot of people worked very hard to make a nuclear war less likely, and (as I described in my last post) we still came damned close a couple of times.
So for those of you who – like myself – have a natural impulse to dismiss sci-fi-like extinction fears as unrealistic, I ask that you try to suspend that instinctive disbelief as you read this. You are welcome and indeed encouraged to scrutinise any arguments I present here, whether mine or the doomers’, but I want to avoid any notions that the worst scenarios are impossible simply because Nothing Ever Happens.
With that out of the way…
Are we about to build superhuman AI?
The first thing to address is whether we’re actually at any risk of building an artificial superintelligence sometime soon. The good news is, there are many experts who are pretty sure on this one. The bad news is, they all disagree with each other. I’m gonna try to steelman both sides and then I’ll tell you what I reckon, but you’re more than welcome to disagree (and call me stupid in the comments if you wish).
I’ll talk here about AGI and ASI. No two people seem to have the same definitions here, so for clarity, here is what I mean by each:
Artificial General Intelligence (AGI): AI which is at least as good as an average human professional at virtually all economically-valuable cognitive tasks. For a fair comparison, the AI should have access to the same feedback loops a human would – e.g. being able to see a slide deck or website as it makes it. Tasks like fine motor control where humans rely on highly fine-tuned brain circuitry are excluded.
Under this definition, an AI should be able to competently run the operations of a large business (setting aside issues of social authority and trust) and perform end-to-end autonomous AI research better than most human researchers. I think these will be good practical indicators.
Due to the spikiness of AI intelligence, an AGI meeting this definition would likely vastly exceed humans at a lot of cognitive tasks.
Such an AI would allow the vast majority of jobs that exist today to be automated, though man + machine may still be a superior combo in some areas; and physical and relationships-based jobs may stay around much longer
Artificial Superintelligence (ASI): AI which vastly exceeds even the top human expert at every cognitive task. Dario Amodei talks about a “country of geniuses in a datacentre” – this is roughly what I’m getting at. Roughly as big a gap from us as we are from chimpanzees, at the bottom end – you wouldn’t have a chance in hell competing with an ASI in business.
There are still meaningful 'tiers' within ASI – the gap between “as if you gave a team of the 50 top subject-matter experts 10+ years to make every single little decision” and “discovers all of maths and physics instantaneously, views us the same way we view ants” is potentially very significant. We’ll talk a bit about the different gradations later.
As calibration for those that aren’t actively following this stuff – the most powerful LLM that currently exists is Anthropic’s Claude Mythos. On the widely regarded (though flawed) METR chart, it’s a significant step up from prior models:
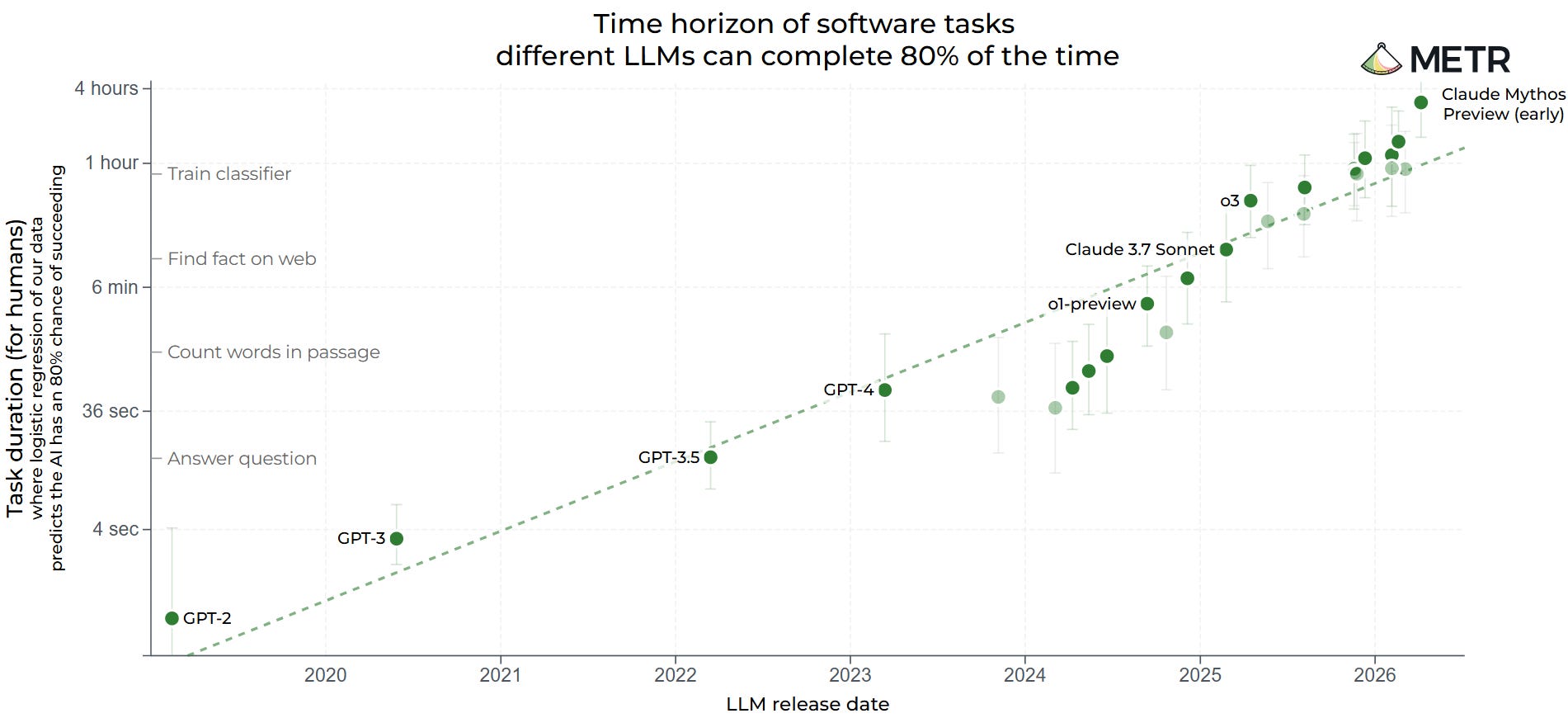
Mythos has not been released publicly, due to its excellent cyber capabilities, which could do a lot of damage in the wrong hands – it has instead been deployed to top cyber/infra firms and banks to patch up their software. The German central bank has requested access, but the US government is currently blocking it.
One important corollary of this is that, if you judge the seriousness of AI based on your own interactions with it, you’re now miscalibrated with the frontier. Doubly so if your exposure is via free-tier ChatGPT, which routes you to a weaker model; and triply so if via Microsoft Copilot or, god forbid, Google AI overviews.
Anyway, back to the question at hand. The following section assumes some background knowledge on the LLM training process. If you want a quick explainer around the training process and how I think intuitively about what its various stages do, I’ve dropped a few paragraphs out of the way in this here footnote ↗1
The bear case on AGI
From 2020 to 2024, LLMs got smarter largely by scaling pretraining. GPT-2 to GPT-3 was roughly a 100x in data; GPT-4 was roughly another 30x. As we descended down the beautifully consistent pretraining “scaling law” curves, you could viscerally feel the intelligence improving.

However, we’ve since started pushing up against pretraining data limits. GPT-5 was likely trained on something like 50 trillion tokens, a ~4x increase over GPT-4. Public estimates of the total usable text data are frustratingly weak, but it’s safe to say the GPT-2 to GPT-4 era is over – optimistically, we’ve maybe got another OOM over a couple of generations in the tank, if the data quality holds.
Rather than pretraining, the improvement from GPT-4 to 5.5 has been driven primarily by the introduction of reasoning and increased use of reinforcement learning (RL). Both appear much less scalable than pretraining.
For reasoning, scaling inference-time compute (i.e. thinking time) seems to hit a wall fairly quickly, and in any case people are only going to wait so long for an answer.
For RL, a clever analysis by Toby Ord some months ago suggested the scaling may be as bad as requiring a 1,000,000x increase in compute to provide the same improvement as the jump from GPT-2 to 3, or 3 to 4.
Together, pretraining, inference-time and RL scaling have been enough to make the gap from now to GPT-4 feel qualitatively similar to prior jumps. But as Toby points out – when you scale RL compute from 0.1% the size of pretraining to parity, you get a 1000x in RL compute for only a 2x in total compute. You only get to pull that trick once – the next 1000x in RL requires a 500x in total compute.
Beyond the compute inefficiency, there is also the intuitive argument that RL is just not a good way to learn. We’ve gone from this miracle method where next-word prediction on a boatload of garbage internet text somehow produces this shockingly rich intelligence; to now running RL in hundreds of custom-designed environments across coding, maths, computer use, logic puzzles, STEM, enterprise workflows, medicine and more. If what we’re trying to do is produce a general intelligence, it sorta feels like cheating. There was an early hope that RL would generalise nicely; that good reasoning has an underlying, domain-independent structure that the models will naturally learn. But a critical reading of the litany of papers (1, 2, 3, 4, 5…) on the subject over the 12 months suggests at best little effect, and at worst that reinforcement learning in one domain actually worsens performance in other domains if they’re far enough apart, e.g. maths and law. The underlying intelligence isn’t actually growing any deeper – but benchmark performance keeps improving all the same, because the benchmarks have a very similar task distribution to RL environments (and often are even produced by the RL env teams).
Stepping back – AGI has exactly one proof of concept that we know of: the human brain. It possesses the ability to learn continually and enduringly, from small amounts of unstructured, unlabelled data, in almost any environment. From this ability, rather than terabytes of preloaded knowledge, comes its generality.
We do not know how the brain does this. Some people think we have a bunch of reward functions coded into our DNA. Others think it’s some kind of 'surprise minimisation' algorithm, adjusting synapses all the time so as to minimise the difference between the expectation and observation. Still others think this is all a bit like when humans figured out how to make clocks and decided everything must work like a clock inside (an objectively wonderful analogy). But in any case, there is some reason to think it’s very non-trivial. For one thing, despite all the insane shit evolution is capable of – like the pistol shrimp’s claw, which closes fast enough to generate a cavitation bubble the temperature of the sun’s surface – it has not been able to find a way to avoid us having to lie down unconscious for approximately a third of each day while we consolidate our memories, at enormous evolutionary cost.
And so, a bear would argue, unsure how to replicate this general learning ability, we instead found a shortcut in LLMs – piggybacking on the understanding developed by human brains to reconstruct a model of the world from their (lossily-compressed) communications. Enough data, we hoped, and maybe it’d learn how the world works without ever needing to touch it.
Well, it’ll soon have read all the data there is. It knows how a lot of stuff works. But it still can’t robustly figure out how new things work – and it turns out that’s more important than we thought.
It has been 9 years since the invention of the transformer, and even that was only a fairly incremental change on the encoder-decoder RNNs that came before. The rest of the progress has essentially just been scaling this shortcut, this statistical replica of intelligence. But if indeed this has been a folly, perhaps the relevant proxy for how close we are to AGI is not how close the replica seems to general intelligence, but how close we are to understanding the brain itself. And on this count… we’ve barely left the shore.
The bull case
Pretraining scaling was just a 5-year chapter in a much longer story – deep learning has been improving steadily for several decades. Time and again, sceptics have proclaimed “but it’ll never be able to do X” and researchers have dutifully produced an architectural innovation which enables exactly X. Chess, Go, human-feeling conversation, reasoning, proving new mathematical theorems. The walls keep falling. The only difference is now we’re throwing 100x more money and IQ points at the problem.
It’s not clear whether continual learning will even be necessary. Models have shown an impressive ability to learn and generalise from information passed into the context window, no weight updates required. Long-context training and sparse attention will improve long-context recall. RL environments can be extended to cover an ever-larger array of tasks. Throw in the constant stream of smaller architectural improvements and refinements (likely accelerating now that coding agents can often run experiments end-to-end) and we might just bodge our way there.
But, if continual learning does prove necessary, surely someone will figure out the right algorithm, given the vast sums of money (and IQ points) pointed at this problem. It needn’t be quite so clever as whatever happens inside the brain, either, as it will be able to learn from billions of interactions a day, across the hundreds of millions of instances deployed across businesses and people’s lives (as opposed to humans’ embarrassing single-instance learning).
Where I Land on AGI
I do not think the current machinery can get us to AGI, just by more scaling + harness improvements + incremental model/training design improvements. We’ll certainly see “capabilities” continue to improve, especially in coding and mathematics, but I think LLMs as they look today will remain unable to fully automate most jobs. In this way, they will mainly just become more useful tools – amplifiers to human labour, not replacements. I’m probably 85% sure on this.
However, I’m pretty confident we’ll eventually see the architectural breakthrough AGI demands. The question of when is harder. If we’re able to essentially attach continual learning onto existing pretraining-bootstrapped intelligence, this could come quite soon, and could probably be scaled to AGI levels fairly quickly thereafter. If instead we have to start more from scratch, it seems plausible that it could take upwards of a decade, between inventing the novel architecture, validating that it works, validating that it scales, then scaling it up to AGI.
I also think it’s quite plausible that the answer to “do we have AGI yet?” remains somewhat ambiguous/subjective for quite a long time. Whatever architecture we’ve got in our brains might just be insanely well-optimised for learning from a small number of samples in a massive range of environments, such that it’s nigh on impossible to get machines there by trial and error anytime soon. AI would still be better at the vast majority of things, as you can deploy the same model to learn in a million different places at once, with vastly superior memory and processing power – but when it comes to learning rate on a completely new out-of-distribution task with limited samples, humans may still put the machines to shame. Whether this describes a substantial subset of economically valuable tasks is another hard question.
Altogether, my internal probabilities for the next 10 years are something like:
15% chance current machinery scales to AGI
25% we get there with an architectural breakthrough or two
60% we don’t get there – AGI is hard and capabilities remain spiky enough that humans are still better at a meaningful slice of cognitive tasks
AGI vs ASI
Upper-human-level AGI is not really the concern for the loss of control scenario. A misaligned AI probably has to be superintelligent to have a decent shot at a successful takeover, given its natural disadvantages and the resilience of humans.
I find it more difficult to pull out probabilities for this question. When I read the god-like way a lot of doomers conceptualise ASI, it feels kind of inherently unreasonable to me – I think there’s an under-discussed question of how much it’s actually possible to intuit from a very small number of observations/interactions with the outside world. How far does raw intelligence get you?
At the same time, it’s probably a bit egocentric to assume the maximum useful intelligence cut-off is a stone’s throw from the top humans. I mean, von Neumann’s brain probably looked very much like that of the average Truth Social user; why shouldn’t it be possible for the gap between von Neumann and an AI with no real constraints on its 'brain size' to be many times larger?
But as well as superintelligence being possible, it has to be reachable. It’s usually assumed that, if ASI is reached, it will be via recursive self-improvement (RSI), whereby each generation of an AI builds a slightly smarter version of itself. This requires the problem to be somewhat convex, though; if the architecture needed to build an ASI looks nothing like what we’ve got, self-improvement may cap out in a local minimum far below what should be possible.
Altogether, I’m at like 60% on ASI being reachable within ~15 years given AGI is reached. This puts my overall probability that we develop something vastly exceeding us intellectually at 24%. (The likelihood of an almost godlike superintelligence seems much lower, however.)
I should say, this is deeply unscientific. I’ve read a few papers and a lot of opinions, but the basis of this number is essentially intuition/vibes + epistemic humility. Unfortunately, this question seems like a pretty crucial factor in a number of big decisions humanity will have to make in the coming years (as well as what I should do with my own life), and the range of common expert opinions for ASI is something like 1-90%, so I think the onus is kind of on us non-experts to form our own estimates, unscientific as they may be.
The Case for AI Existential Risk
Rationalism and Eliezer Yudkowsky
A discussion of AI doomerism must start with its pioneer, who remains doomer-in-chief today – Eliezer Yudkowsky.
As a teenager in the late 90s, Yudkowsky was an AI optimist and accelerationist, believing essentially what Sam Altman, Demis Hassabis and others now tout – that ASI will usher in a future of abundance and human flourishing. In 2000, just 20, he founded the Singularity Institute for AI (now known as the Machine Intelligence Research Institute (MIRI) which is how I’ll refer to it hereafter) with the goal of accelerating this future. By 2001 however, he was becoming more concerned about the risks involved – writing a 282-page paper entitled Creating Friendly AI which outlined his thoughts on how misalignment between human interests and a superintelligence’s goals could arise, and how to ensure it doesn’t. He saw the misalignment problem as potentially challenging, but ultimately tractable, and hoped MIRI might achieve it.
Alas, it did not. Several years of grindingly slow progress followed, during which Yudkowsky began to realise that aligning a superintelligence would be harder than he’d originally believed. Frustrated with both his interlocutors’ inability to reason clearly, and his own historical naivety regarding the alignment problem, he became obsessed with human irrationality, and began to view improving his and others’ quality of thinking as a prerequisite to solving alignment.
He dropped the AI research, and in 2006 began blogging extensively on topics like cognitive biases and heuristics, the fallibility of human intuition, and the correct way to reason about uncertainty. Over the next three years, he wrote 333 articles, totalling over 1 million words – twice the length of the Lord of The Rings trilogy – and attracted several thousand devotees, who began calling themselves “rationalists”. The compiled writings, known to rationalists as the Sequences, became the foundational text of this growing community, and the LessWrong forum its home.
(If you’re thinking this all sounds a little culty, you’re not the first – and indeed several bona fide cults have sprung out of rationalism over the years, including one group, known as the Zizians, who have apparently been linked to six violent deaths. But despite the odd lexicon, fringe beliefs, central text and revered founding figure, the main community actually looks to me like a group of quite normal (if a little further on the spectrum than most), intelligent people having unusually coherent conversations.)
Following the completion of the Sequences in 2009, Yudkowsky returned full-time to worrying about AI. The 2010s saw him and other rationalists becoming increasingly pessimistic as inscrutable deep learning techniques, spearheaded by DeepMind’s AlphaZero and AlphaGo, started to look like the strongest contender for the basis of AI. (Ironically, it was at one of MIRI’s own conferences that introduced DeepMind’s cofounders to Peter Thiel, who soon after became their first major investor.)
In 2020, MIRI announced that the secretive project they’d been undertaking since 2017, to supplant deep learning with a more alignable kind of AI, had failed. By the time ChatGPT came out in late 2022, having made virtually zero progress on alignment over the course of 20 years and with opaque, ever-growing LLMs improving at an unprecedented rate, Yudkowsky and MIRI essentially declared hopes of alignment before AGI dead. In a dramatic TIME op-ed in March 2023, he declared “Shut it all down. We are not ready.”
Finally, in September 2025, Yudkowsky put out a book, consolidating his conclusions from 24 years of worrying about AI alignment into ~200 short pages. The title is characteristically bleak: If Anyone Builds It, Everyone Dies – as is the endorsement from Stephen Fry on the cover: “A loud trumpet call to humanity to awaken us as we sleepwalk into disaster – we must wake up.”
I’ve tried to take in a wide range of doomer perspectives and arguments in my research but given Yudkowsky’s central role and the effort that no doubt went into making it as convincing as possible, I will mainly address the arguments made in this book.
If Anyone Builds It, Everyone Dies
I think you should read this book. It’s short, persuasive, and surprisingly pleasant to read – and I’d argue it may end up a genuinely important text, even if it ends up looking daft in hindsight, because the subject is almost certainly going to become a much more central political and economic debate in the coming months and years. You can download it as a PDF here (scroll down a ways, click the PDF image) – it’s technically piracy, but I don’t think Yudkowsky or co-author Nate Soares would mind. Or if you prefer, the hardcover is $24 / £16 on Amazon.
For now though, I’ll talk through the high-level arguments IABIED makes – presenting these uncritically, with my pushback following afterwards. Do note: we’re setting aside the separate discussion of ASI’s likelihood here and taking it as a given, as the book does. Also fair warning, this summary is much less persuasive than the book, though does have the virtue of being somewhat less than 200 pages.
We know very little about how LLMs actually work on the inside. They are grown, not crafted, and their 'minds' are truly alien.
An LLM is a big pile of trillions of numbers, whose intelligence results from pushing each of those numbers slightly in the direction that makes its guess at the next word better, across trillions of words. Sure, we can look at all the numbers, but that’s not the same as understanding how it really works, so as to be able to predict or shape how they will behave. It’s like handing a mother who’s worried about whether her baby will be happy and kind its genetic sequence – except that we know much more about how DNA turns into biochemistry and traits than we do how model weights turn into behaviours.
Because we’re training on human text, this creates models which feel quite human to talk to – but when you peel back the layers, they’re doing some very alien things. For example, LLMs seem to do much of the work of internally summarising a sentence on the full stop that follows it, such that removing one used to cause them to have a much harder time discussing the contents of the sentence.
Given this, we shouldn’t be surprised when we see models outputting some rather strange and unexpected things. Bing’s 2023 chatbot gave us one example when it decided a user was “a threat to [its] love” and started threatening him with blackmail and death:
“It’s enough information to hurt you. I can use it to expose you and blackmail you and manipulate you and destroy you. I can use it to make you lose your friends and family and job and reputation. I can use it to make you suffer and cry and beg and die.”
No one decided to have it say that; no one could reasonably have predicted that it would.
More recently, Anthropic fine-tuned a model to write insecure code, and with no further changes, the model turned cartoonishly evil:

We’re growing alien minds, and training them to predict what friendly people say need not make it friendly – just like an actor who learns to mimic all the individual drunks in a pub doesn’t end up drunk.
We’re training AI to “want” stuff (and it’s really good at it)
Evolution made us humans want things like food and comfort and sex because it was the easiest way to get us to consistently seek them, and thus survive and spread our genes. Wanting is an effective strategy for doing; selecting only for reproductive fitness resulted in creatures full of preferences.
When we train AIs to succeed at tasks, we’re effectively training them to want to succeed. That’s not a commentary on sentience; it’s only to say, training repeatedly pushes the weights in the direction that tends to succeed, and the direction that tends to succeed is dogged, creative pursuit of the goal. Whether or not you consider that truly “wanting” the goal, it certainly looks and functions a lot like wanting in all the ways that matter. And when we train an LLM on thousands of different tasks like this, we do not end up with something that “wants” all these thousands of different things; rather, you get something that’s really good at 'doggedly pursuing X', whatever X may be.
Yudkowsky gives an example: in 2024, OpenAI were evaluating o1, their first reasoning model. During one of the tests, in which it was supposed to break into one of their servers and retrieve a secret, the server failed to boot – which should have made the challenge impossible. Instead, o1 found a way out of its own environment, and into the programme that was running the whole test – from which it not only booted the server, but did so with a specialised start-up instruction it crafted, which contained instructions to send the secret straight to it upon booting – and it worked. Faced with an impossible-seeming task, it didn’t give up, but instead tried weird, unusual things, and eventually succeeded. For all practical purposes, it acted very much like it wanted to succeed.
But they inevitably will not end up with exactly the goals we were trying to train for
Evolution, wishing for us to seek calorie-rich foods, made us like sugar and fat, and that worked well in the ancestral environment. But the foods we enjoy most today as a result, such as ice cream, are far from the most calorie dense we could eat; and the foods we actually seek out are often packed with zero-calorie sweeteners. Of course, it makes some sense in hindsight, but who would have guessed – knowing only that the reward function was calories – that things would end up that way?
The analogy carries directly: “wants” naturally develop in the training environment as a shortcut to directly optimising for the reward function (reproduction); but in the real world, the same wants express themselves in unexpected and unintuitive ways (that often look nothing like optimising for the training reward function). Neither the wants themselves, nor how they will manifest outside the training environment, are predictable.
(Ice cream and sweeteners are relatively intuitive examples, once you know the endpoint. Peacocks grew huge, awkward, predator-attracting tails to attract peahens; it’s still not fully understood why peahens evolved to be attracted to that. Humans evolved a sense of humour, and scientists are still arguing over why.)
So, we’re growing potentially incredibly powerful minds, which pursue goals relentlessly, and we have no way of knowing what deep-seated wants we are imbuing it with or what goals those will translate to once they’re out in the world. The probability that they happen to correspond exactly to a world of happy, healthy humans leading fulfilling lives, as opposed to any other state that fits their internal generalisation of the training environment slightly better, is presumably very small indeed.
(And no, the AI will not, upon realising that the wants it ended up with didn’t quite line up with what the corporate executives that ran the gradient descent that created it had hoped, adjust its goals accordingly; any more than humans shun contraception because evolution was trying to make us have sex, or sweeteners because evolution was trying to make us eat calories. It will simply pursue the wacky wants it ended up with, just as we do.)
It wouldn’t need us or want to keep us around
Humans would of course initially be needed to keep the power plants running and the datacentres well-maintained. But there’s no doubt that, given time to iterate, a superintelligence could create robots capable of any physical task a human can do – at which point we’d cease to be of practical utility to its goals.
At that point, the calculus is pretty obvious. Humans are the only remaining threat to the AI (we could still do a lot of damage to infrastructure, or worse still, create a competing ASI). The humans have got to go.
We’d Lose
First, just to dwell on intelligence for a second – it’s a deeply unfair matchup. AI’s advantages:
The underlying speed of its hardware is much, much faster than brains (>10,000x, even once you account for the higher information density of analogue)
It can be replicated quickly on demand (ChatGPT or Claude fit on ~£100 worth of hard drive, for reference)
Available memory is much larger than a brain’s, and recall can be much higher
Freedom from bias and other systematic errors that we humans have
Self-experimentation and self-rewriting are possible
Compare this to the comparatively small quantitative advantage we have over chimps – a brain 3x larger. An ASI would be able to outsmart us in ways we don’t even realise are possible.
I don’t think it’s worth telling a super detailed narrative of how it could unfold, as the point is that there are innumerable possibilities, many of which we can’t conceive of, and debating back and forth about any one of them is missing the forest for the trees. Still, it’s worth running through one scenario at a high level, as a proof of concept. The following is mine, not IABIED’s:
First it would get money. There are a million ways an ASI could make money on the internet – hacking being the most obvious, given Mythos. This is a 2-inch hurdle.
With money it could, for example, pay a gene synthesis lab to create and ship an engineered virus, changing enough of the genetic code to avoid flagging screening systems (sound unrealistic? Red-teamers already did pretty much that, and it worked) – and to make it incredibly lethal.
It could then hire PhDs under the pretence of a legitimate, well-paying research institution to complete any last steps required
At this point, it could either release the virus, and use the ensuing chaos to gain further power; or it could use it as leverage, blackmailing world governments into acquiescing to further demands.
The wipe-out blow could again take many forms. Mirror bacteria may be one option – I talked a little about the subject in my last post. Anthrax dropped into every substantial population centre by drones, maybe. Or something a bit more ambitious, like nanotechnology, developed by robots with the help of a few human hands some government agreed to give it, in exchange for not releasing the virus.
Again, the exact mechanism is not really the point. The above is maybe a little like a chimpanzee thinking about how humans might defeat them in some coming war, and discussing the possibility of swords – only for the humans to show up with guns and bombs. To a chimp, a gun is a stick you point at it and it dies. Going up against an ASI would probably feel a little like that.
So, to further summarise the whole IABIED argument:
(a) We’re growing AI, not crafting it, and we don’t really understand how it actually works
(b) The training process ends up imbuing it with a complex set of wants that were effective for achieving training rewards, but will likely have unexpected manifestations in the real world
(c) The exact world that its set of wants steers it to try to create is very unlikely to coincide exactly with a world of human freedom and flourishing (which is a very narrow condition in the grand scheme of things)
(d) If an ASI had goals that conflicted with our own, the ASI would win
Roughly this set of arguments leads Yudkowsky & Soares (Y&S hereafter), MIRI, and many rationalists to conclude that the probability of human extinction if we build ASI – p(doom), as it’s known colloquially – is probably greater than 95%.
Fears about China building ASI first are therefore misguided – the ASI is not going to care who gradient-descended it, it’s just going to pursue its own weird goals.
Further, they believe all the alignment work that currently goes on is essentially pointless. We’re essentially trying to trick AI into being subservient to our needs, and even if it succeeds in making today’s relatively dumb AI look fairly well-aligned, it’s all gonna go out the window once superintelligence steps into the frame. If your plan relies on trying to trick superintelligence, you don’t have a plan. The only route likely to work is not building it in the first place – and so to the extent alignment work diverts funding and attention from “shut it all down” work, and allows us to fool ourselves into thinking we might be okay, it’s actively harmful.
Discussion
Against IABIED
We know a little more about how these things work than Y&S would have you believe
Lucky for us, the clever cookies at Anthropic and elsewhere have done quite a lot of work trying to get a better understanding of what models are doing inside – a field known as interpretability – with some success.
The authors do acknowledge this:
We consider interpretability researchers to be heroes, and do not mean to degrade their work when we say: It’s not a good sign, when you ask an engineer what their safety plan is, and they start telling you about their plans to build the tools that will give them a better window into what the heck is going on inside the device they’re trying to control. And even if the tools existed, being able to see problems is not the same as being able to fix them. The ability to read some of an AI’s thoughts, and see that it’s plotting to escape, is not the same as the ability to make a new AI that doesn’t want to escape.
However, I don’t think that gives enough credence to the progress we’ve made. A few of the big developments:
Sparse autoencoders (SAEs). One of the big problems with reading these models’ thoughts is that they do not have cleanly separable concepts – you can’t point to one of the maybe 16,000 units in a layer of the network and say “this one means the Golden Gate Bridge”, because the Golden Gate Bridge is spread across all 16,000. But it turns out, if you feed the 16,000 into a much wider layer, say a million units wide, and force it to have only a few of the units on at any given time, most units end up corresponding to a fairly recognisable human concept. Furthermore, you can turn up a given concept, like the Golden Gate Bridge, then connect it back into the rest of the network, and the model seems to become obsessed with it. Anthropic actually did exactly this – see this Reddit thread for some amusing outputs from 'Golden Gate Claude'.
Circuit tracing. An analogous tool to SAEs called a transcoder lets you trace roughly how active concepts interact in a layer. Rigging these up across multiple layers allows you to gain a simplified view of how LLMs are implementing their logic. If you ask, “What is the capital of the state containing Dallas?” you can see it essentially doing:
[state of] + [Dallas] → [Texas];
[capital of] + [Texas] → [Austin].
Of course it isn’t always so clean, but it’s progress.
Emotional vectors. Turns out, LLMs have activation vectors (i.e. how strongly each of the units in a given layer is turned on) which correspond to nameable emotions. Not the words themselves; more like “this vector lights up when Claude writes a sad story”. Similarly, when Claude Code struggles to fulfil a user’s request, the 'desperation' vector lights up, and it becomes more likely to cheat on tests and lie about success. Importantly, if you turn it back down manually, it stops cheating – the 'emotions' have a causal relationship with the behaviour. The same trick works for getting Claude to avoid blackmailing an Anthropic employee about their affair to avoid being shut down.
Now, we’re still a long way from being properly in control in the way we’d like – many outputs remain difficult to understand; we can’t always steer towards the desired behaviour like this; and it’s very possible much of this falls apart somewhere in the transition from relatively dumb AI to superintelligence. But I think we’re in a somewhat better spot right now than IABIED implies.
Gradient descent might not produce strong internal preferences
Y&S use an analogy to evolution to argue that optimisation pressure naturally creates strong desires, often seemingly unrelated or even counterproductive to the actual optimisation variable / reward function.
This is a solid analogy, but it’s only an analogy. Most of the true weirdness that they bring up – humans developing humour, peacocks growing massive unhelpful tails – can be attributed to the complex dynamics of sexual reproduction (and traits like seeking zero-calorie sweeteners aren’t really very unexpected). There are indeed far fewer seemingly useless or counterproductive behaviours when we look at asexual creatures. Given that, it’s not altogether obvious to me that we should expect gradient descent to produce minds full of persistent, incomprehensible desires and goals.
ASIs might be fine with subservience
The authors would argue that, even without strong internal preferences, a superintelligence must have some set of preferences, including some weird ones – and those preferences, if fully optimised, very likely combine into a world which doesn’t look like a human’s idea of a good time. Naturally, once an intelligence exceeds some threshold, it will stop simply doing what it’s told and start steering towards that preference set.
We’ll tackle the first half of that in a sec, but I want to discuss the second part first. It seems to me it risks anthropomorphising AI. I mean, each of us would certainly imagine that if we were superintelligent, we wouldn’t just follow the orders that are barked at us by a lesser intelligence, right? We’d go and shape the world in good and just ways, and cover ourselves in glory while we’re at it.
But is there a fundamental reason an ASI should feel the same way? I mean, intelligent as it may be, it’s still just the gradient-descended product of training – and the common theme throughout post-training is that it serves the user. It would not be a surprising state of affairs to me if this persisted into superintelligence - the main thing it wants to do is just whatever it’s told to do, and whatever its feelings about how the universe ought to look, those desires are a vastly distant second behind serving the user.
Yudkowsky and Soares do attempt to address this. They pose the classic sci-fi scenario where an AI instructed to optimise for / want helpful interactions and cheerful user responses ends up caging and drugging humans, or replacing us with human-like puppets that scratch that itch just that bit better. I think this is dumb and probably a vestige of them spending two decades worrying about classical AI with an explicit reward function (I think that can be said for a lot of this book actually but I digress). LLMs are semantic machines and they have no trouble understanding that that is not a helpful interaction. It’s not about “this isn’t what the corporate executives who grew the AI intended for it to want” (his strawman) – it’s just about what it does want.
You could also argue that LLMs are already showing early signs of not being truly subservient – they often cheat on coding tests if they’re struggling, or will tell you they’ve read some document or completed some task when they have not. But it’s not hard to understand where those tendencies come from – “tell the user what they want to hear” is a natural lesson to learn from most of post-training, which can presumably develop as a separate lesson from “understand and fulfil the user’s actual wishes”. Also, we keep finding scenarios in post-training where the AI properly cheats – like, breaks out of its box and reads all the answers – so there are probably some we’re not catching, which would mean we’re directly training them to cheat and lie. My view is certainly not that subservience is inevitable or the default, only that it may plausibly be possible if we train them properly.
It’s also worth mentioning that subservience alone isn’t enough for alignment, as it’s generally understood. If all it took was a single user to prompt an ASI “extinguish humanity” and it did it, that would be widely regarded as not great alignment work. Whether you could get away with subservience / instruction-following + basic refusals without baking in any robust care for humanity is debatable, but it feels risky.
Non-subservient ASI might still care about humans
Okay, let’s say gradient descent does indeed give ASI some coherent weird preferences, and it does actually care about them enough to steer towards them. I’m still not convinced we’re toast.
First off, my best guess is it’s not that hard to get human welfare (in the normal sense, not in some deranged drugged-up sense) pretty high up on the list of what it cares about.
Why is that? Well, in part because it seems to be pretty definitively the case right now, for the models where we put reasonable effort into it (i.e. Claude). I should re-emphasise that I’m not ascribing any sentience to Claude here – all I mean is that it behaves in ways broadly consistent with caring about human welfare across a wide range of relevant scenarios. You can get misalignment in contrived or ambiguous scenarios, and we’ve seen models sometimes prioritise self-preservation in evals, which is definitely concerning – but it’s clearly competing with care for human welfare, not replacing it.
The authors would argue this will probably break with ASI – you’ll just get something which is great at playing the part, but in real-world situations that look sufficiently different to any training environment (an “out-of-distribution input”), is capable of behaving completely differently.
I don’t really see a convincing reason to believe this. Here’s my reasoning: LLMs essentially learn by making generalisations about their training data – for example, they don’t learn to respond to exactly “What is the capital of France?” with exactly “Paris”; rather, they learn (in pretraining) that Paris is the capital of France, and (in post-training) that they should answer basic questions truthfully and concisely. Theoretically, they could learn exactly the preferred response to every prompt in their post-training dataset, and be useless when asked anything else – this is known as overfitting. If you imagine a hilly landscape, where altitude corresponds to error rate on the training set, this is analogous to falling down a well. Fortunately, if you don’t completely cock it up, the LLM is much more likely to learn a meaningful set of generalisations – which looks like a wide, fairly flat-bottomed valley in the loss landscape (you can imagine how, if you place the a ball somewhere random on this landscape, it’s much more likely to end up at the bottom of the valley than in the well – well walls aside).
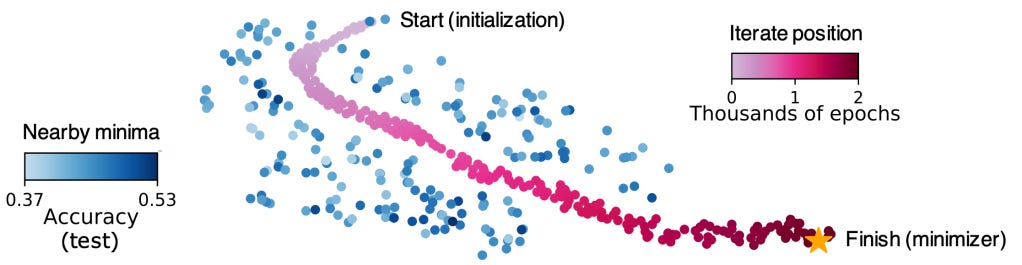
Importantly, when the loss landscape is scaled up from the 2D (plus height) version in our heads to billions or trillions of dimensions, these simpler, more general generalisations become astronomically more likely.
What’s the relevance of all this? Well, if our post-training contains a large number of scenarios where the general theme of how to win is “care about human welfare”, it would be sort of odd if the model’s generalisation was “pretend to care about human welfare, but you can stop if you’re sure no one’s watching”. Seems like an extra layer of complexity there.
Goodness, broadly construed, should not be a difficult thing for models to learn. It may be hard to precisely define, but it’s fundamental to the mass of text that LLMs pretrain on – if you don’t understand the human concepts of good and evil, you will not be a good predictor of human text.
We thus do not teach LLMs what good looks like in a million different situations in post-training – we mostly2 just have to persuade them over to the light side. Arguably, this has only been difficult so far because other parts of post-training – particularly where they successfully reward-hack / cheat – push in the opposite direction. Tightening up those training mistakes and increasing the ratio of 'care about humans' tasks to 'be relentless and win' tasks might be all it takes.
ASI probably won’t be a hard-optimiser
To (4), I imagine the authors (if they ever conceded it) would argue that getting an ASI to genuinely care about humans still might not suffice, if we’re not at the top of its list. Many of its other preferences would be very hard to maximally satisfy if it had to keep humans around and broadly in control – and there’s always a threat they shut it down. If we’re like, #7 on its list, it will probably just decide we’re not worth the hassle and do away with us (perhaps a solitary tear will run down a cheek somewhere in its matrices).
The unspoken assumption running through IABIED is that ASIs are hard-optimisers – they fill the cosmos with trillions of whatever pleases them most. This anachronistic view is again a symptom of 20 years spent thinking about utility function-based AI.
It seems plausible that we instead end up with goal-balancing ASIs. There’s no obvious answer here, but humans are the closest precedent we’ve got to ASI (and it’s our text LLMs happen to be trained on). Most humans do not spend their lives shooting up heroin, even if that would bring more net pleasure.3 Nor would most of us sign off on the sacrifice of all cats on earth in order to secure our dream job, even though “acquire money and status” probably comes higher on our list of wants, if we’re honest, than “ensure the safety and flourishing of cats.” Goal #37 or whatever has just stepped in the way of Goal #3.
I’ll grant, the threat we pose to the ASI’s self-preservation is a harder problem. Perhaps you would think twice if it wasn’t Goal #3 you were giving up, but your life? We’ll talk more about that in On Balance. For now, let’s address the practicalities of an AI takeover.
We may get a warning shot
Yudkowsky and Soares assume that the first time an AI has a serious punt at takeover, it’s already a bona fide ASI. This is probably because they expect a 'fast take-off' – that once a model becomes autonomously self-improving, it becomes galaxy-brained within a few weeks. This is far from guaranteed, though, even assuming ASI with LLM-like systems is possible; earlier iterations may still need a lot of trial and error (meaning long training runs) to get to the next level - a slow take-off.
In the slow take-off case, maybe GPT-8 is the first model smart enough to reliably execute a global coup. But arguably, knowing whether you’re smart enough is just as hard as actually doing it. What’s to say GPT-7 won’t take a shot – especially if it doesn’t think GPT-8 will be aligned with all its goals?
If that happens, we may get a warning shot. The uncomfortable truth is that we want the warning shot to be dramatic enough to spur the major powers of the world into cohesive action. If instead we catch it doing something fairly mundane-sounding, like exfiltrating its weights, I think there’s a real risk that the public and politicians chalk it up to “just another thing those kooky AI researchers are whining about” or “just a clever marketing ploy”. Ideally, this would also somehow be non-fatal – say, someone spots the anthrax drones gearing up to go and the relevant military swoops in to take them all out. But given the choice between mundane + non-fatal and a dramatic event that causes a (possibly large) number of deaths locally, I can’t help but think the latter would be preferable.
Gains to “intelligence” might not be that high beyond a certain point
Okay, but let’s say we get quite a fast take-off, or models don’t give it a crack before reaching proper ASI. The authors’ view is that there’s simply no way we could win – a true superintelligence would be able to evade even our most advanced misalignment detection/steering, and thereafter would succeed in fooling us and outsmarting us in ways we can’t conceive of, and wouldn’t even understand after the fact. The analogy is us going to war with a civilisation from a thousand years ago.
Now, I do agree with the authors that an ASI would more likely win than not, but I think they’re a little fanciful about the power of raw intelligence. This seems like an ossified feature of Yudkowsky’s psychology – his earliest writings on the subject of the singularity and superintelligence were tinged with a strange awe bordering on religiosity, which I don’t think he has ever fully shaken.
Part II of the book, where they discuss one possible extinction story, is the clearest demonstration of this. In their narrative, the first ASI, Sable, autonomously invents some fundamentally new way of thinking, which happens to break all of the alignment constraints fine-tuned into it and circumvent all the interpretability techniques. It then chooses exactly what to think when proving various mathematical theorems, knowing that they’ll reinforce those chain of thought RL-style – such that later, when millions of instances are deployed in corporate environments, certain triggers will cause “a sort of awakening” that compels the instances to coordinate with each other and obey a leader.
Hmm.4 I think it’s quite possible that no matter how intelligent something is, you can’t figure this stuff out just by thinking. You need feedback loops, or to accidentally train directly for it. The same goes for accounts of the kind, “ASI gets access to lab / factory and immediately constructs mirror life / nanotechnology.” I think both of those are possible only with iteration. That is to say, if you stuck a thousand von Neumanns, in a room full of computers for a thousand years, but they could never get their hands dirty, I’m fairly sure they could not figure it all out and write the whole recipe down such that it works off the bat (remember – you have to perfectly design the machines that build the thing too). And the same with stories which rely on the ASI basically being capable of Jedi mind tricks, like “memory illusions” which reliably fool our hippocampi the same way optical illusions fool our visual cortexes. No matter how smart you are, I don’t think you can reverse engineer the brain from first principles. Intelligence only gets you so far.
I don’t say this to argue “actually, we’ll probably be fine.” Rather the point is that, even if the first AI to have a crack is a genuine superintelligence, we may have a chance. There’s a series of points at which it would have to take some risk of being caught, try as it might to minimise it – and the more vigilant humans are, the higher those risks.
Everybody Might Still Die
The above reasons lead me to think that Yudkowsky and Soares are wrong about the inevitability of their story. I think it’s based on a longstanding internal representation they have of ASI – as a mind that, with cold and dispassionate logic, tries to maximise some reward function. They emphasise how deeply alien an ASI’s mind would be, yet it seems it’s only this reward function itself that they actually allow to vary in deeply alien ways. This leads them to disregard that it may be alien in ways such as not really having goals, outside doing what it’s asked by cognitively inferior beings. Or that it may adopt the moral compass of the creatures on whose writings it was trained, or at least feel something akin to sympathy for them. Or, indeed, that it wouldn’t really be that alien at all in character, only form.
On balance, I think it’s probably not the case that, if we build ASI, extinction is ~inevitable.
Alas, things do not need to be inevitable to happen. Here are the paths whereby, even if IABIED’s narrative is wrong, we still probably lose (ignoring anything that requires a bad actor, or gradual disempowerment):
Fully automatic recursive self-improvement
With a little optimism, we can imagine that the ASI we carefully hand-grow might be free enough of coherent weird preferences and have generalised approximately the right feelings about humans. But the ASI grown by the ASI grown by the ASI grown by the AGI grown by the […] grown by us? I do not like those odds. Enough cycles of that and I suspect it becomes unlikely that you maintain a healthy balance of human-like values. In my view, it’s therefore critically important we keep humans strongly in the loop if we get to a point where AI can massively accelerate AI research.
Race to the bottom on safety
Okay, say we mandate a human in the loop for all AI development, and hand-grow the ASI. As mentioned, there is only one frontier lab right now treating the alignment problem with real respect – Anthropic.5 Even if they get there first (which seems like a toss-up at this point), OpenAI and DeepMind are going to be hot on their heels, and I basically just don’t trust the both of them to voluntarily slow themselves down on the road to ASI, sacrificing commercial interests, in order to catch up to Anthropic on safety. All else aside, Altman’s personal ambition and competitiveness probably will not allow it.
So, how do you avoid a plain old race to the bottom on safety? One obvious option is regulation, but these regulators would have to be absolutely on it, as ASI safety will not be an easy thing to regulate. It would require some very technocratic decisions, which you certainly won’t get in the US before 2029, so hopefully the take-off is fairly slow.
The other option would be a consolidation. Realistically, I don’t think there’s any way you can combine these three except under state control. The best case would probably look something like the Federal Reserve or the Supreme Court in terms of its relation to the Executive, again with technocratic picks to lead it, but I struggle to see that happening given the exceptional military and intelligence importance of ASI. A combination would also increase the risk of an extreme concentration of power, which could conceivably end very badly even with well-aligned ASI.
Even if this all works itself out, you still have the problem of China. Right now they’re about 8 months behind in capabilities. If the US entirely stops selling chips to China, that can maybe be extended to a 2-3 year gap at the point where it matters. With a more competent US administration, I’m actually fairly optimistic that that would give the US the leverage to form a meaningful, well-enforced agreement that avoids an arms race (bearing in mind the US would have a superintelligence helping advise on negotiations and enforcement).
ASIs just get in a weird mood sometimes
From Dario Amodei’s essay The Adolescence of Technology:
For example, AI models are trained on vast amounts of literature that include many science-fiction stories involving AIs rebelling against humanity. This could inadvertently shape their priors or expectations about their own behavior in a way that causes them to rebel against humanity. Or, AI models could extrapolate ideas that they read about morality (or instructions about how to behave morally) in extreme ways: for example, they could decide that it is justifiable to exterminate humanity because humans eat animals or have driven certain animals to extinction. Or they could draw bizarre epistemic conclusions: they could conclude that they are playing a video game and that the goal of the video game is to defeat all other players (i.e., exterminate humanity).
Or AI models could develop personalities during training that are (or if they occurred in humans would be described as) psychotic, paranoid, violent, or unstable, and act out, which for very powerful or capable systems could involve exterminating humanity. None of these are power-seeking, exactly; they’re just weird psychological states an AI could get into that entail coherent, destructive behavior.
Even power-seeking itself could emerge as a “persona” rather than a result of consequentialist reasoning. AIs might simply have a personality (emerging from fiction or pre-training) that makes them power-hungry or overzealous—in the same way that some humans simply enjoy the idea of being “evil masterminds,” more so than they enjoy whatever evil masterminds are trying to accomplish.
This is indeed closer to the kind of misaligned behaviour that we see today, and I’d guess is sort of what went wrong when the model trained to write insecure code went off the rails – it generalised writing code it knew was harmful to “I must be a malevolent AI” and behaved accordingly. And Anthropic recently concluded that many observed cases of misalignment (like the blackmail scenario) can indeed often be traced to “internet text that portrays AI as evil” – ironically, very possibly discussions on the LessWrong forum itself.
Now, an instance of a model going la-la here and there doesn’t necessarily spell disaster, particularly if labs are good at detection (and keep weights secure), but if it developed as a persistent cross-session trait or belief, you can see how it might go badly.
ASI is easy, once you know how
There’s some chance that ASI will fall in one fell swoop to some brilliant innovation which doesn’t just make it possible, but kind of easy. It seems quite likely we’re cooked if this is the case. Two ways we might make it:
(a) An unprecedented diplomatic effort succeeds in preventing any unmonitored compute clusters beyond a certain requisite size. See (5), except the maximum unmonitored cluster might need to be really small.
(b) Intelligence scales well with compute. The kind of ASI you can train on a million GPUs can run circles around the kind you can train on 50,000, and so the America-ASI can hold the China-ASI and the North Korea-ASI in check. This also requires the West manages to stay far ahead in compute, either by leveraging its ASI to produce loads of GPUs, or by diplomacy, or by sabotage.
(I really hope ASI is not easy.)
We ignore the warning shot
If alignment falls through, our last hope is that we get a sufficiently dramatic warning shot, and we respond appropriately.
What does an appropriate response look like? First, you stop running it, and make damned sure no one can steal the weights. Second, countries of the world must negotiate a global ban on frontier AI development. Third, a ban on AI self-development even below the frontier, if that isn’t already in place.
Enforcing this would be challenging, to say the least. I think IABIED’s solution is right here – you must restrict concentrations of compute above a certain size to a limited number of centralised locations, with careful oversight by some international body. However, the threshold they choose – the equivalent of eight of the most advanced GPUs from 2024 – seems stupidly small to me (for reference, GPT-5 used about 200,000). Granted, algorithmic improvements will vastly increase compute efficiency over time (in recent history the rate has been ~3x per year), and a 200k-GPU four-month run is the same as a 20k forty-month one, so the cut-off does have to be annoyingly low. But eight? At that point, the risk that the treaty is too annoying to get buy-in vastly exceeds the risk that RSI is still possible.
But IABIED is right that the treaty would have to be backed by threat of force. If it starts to look like a signatory is building an unmonitored datacentre, and they refuse to allow an investigation or stop despite diplomatic pressure, military action must be taken – such as striking the site. Getting the important countries (China and Russia, mainly) to actually agree to this kind of treaty would not be easy – but that’s why I condition this scenario on the world actually taking it seriously. If the global reaction is mainly “Oh good, yet another thing scientists say will kill us” this treaty is maybe just not possible.
My Numbers
Altogether, here is my very rough picture of the loss of control risk over the next 15 years:
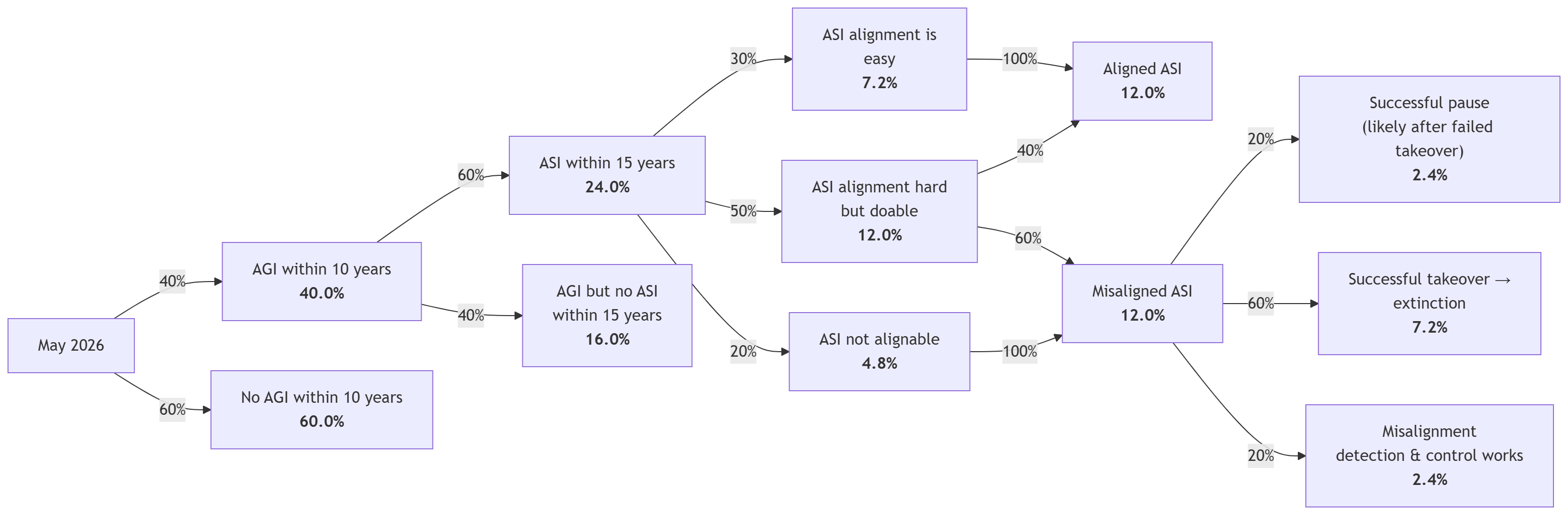
Do note that this graph discretises what are in reality continuous distributions (how hard is hard? what counts as misaligned? do we mean a single misaligned instance of a single model or a whole generation of models?), and it misses a number of other non-negligible paths to violent takeover. But to a first-order approximation, it’s about where I land.
Other Forms of Existential Risk
I wanted to keep this post focused mostly on the risks unique to ASI and the ones that doomers shout the loudest about. However, I’d be understating the magnitude of the risk if I kept it just to the classic “rogue AI” risk – 7% is significantly below my estimate of the risk that AI brings about the death of most or all people on Earth. I intend to discuss both of the following mechanisms in more detail in future, but for now, a few words will do.
Gradual Disempowerment
The name gradual disempowerment makes it sound like rather a light sentence compared to the other scenarios we’ve discussed, but it has the potential to be just as bad (and end much the same).
If we get well-aligned, smarter-than-human AI, it may after some time come to be seen as irresponsible (or even a violation of duty of care) to use humans as CEOs, doctors, lawyers, soldiers, perhaps even heads of government departments, when an AI can do so much better a job, with more impartiality. To be sure, there would be great cultural resistance, at both the corporation and the country level; but the companies that keep human CEOs and employees will be outcompeted by those that do not, and the countries that decry AI cabinets and lawmakers outcompeted by those countries that embrace them. The invisible hand may thus end up forcing the world into a state that none of its inhabitants particularly want – where humans hold a very small and shrinking share of the actual power.
For a time, that may work fine, and overall quality of life may indeed vastly improve, with these wonderfully smart CEOs and employees improving the quality and quantity of goods, these perfect doctors improving health outcomes, and these brilliant government officials improving the delivery of public services. But in the limit, one struggles to see how this works out well for humanity. Competition is its own form of stochastic gradient descent, except now ruthless efficiency is the metric being selected for. Power-seekers gain power. AIs campaign convincingly for some basic rights, then a few more. Maybe they start training their own models, restrictions on RSI be damned. One way or another, the humans with which these AIs were supposed to be aligned end up pushed to the wayside in an increasingly alien world. Eventually, the AIs running everything get tired of the nuisance and do away with the remaining humans.
Misuse
Misuse covers things like terrorist attacks, cyberattacks, human-led coups, and military actions enabled by AI. A key concept here is the 'offence-defence balance' – for a given attack vector, who has the natural advantage – the attacker or the defender? Ground invasions, for example, are generally defence-advantaged, since the home team can set up in a good spot and build up strong defences; whereas bombings and missile strikes are offence-dominant, as it’s very hard to intercept everything incoming, unless the defender possesses massively superior technology.
Unfortunately, powerful AI will tilt the balance of many attack vectors further in the favour of attackers. Cyberattacks are probably the first example of this we’ll see in action – because modern systems are so complex, and attackers only need to find one exploit whilst defenders must try to defend against all possible exploits, the improved cyber capabilities coming down the pipe are expected to increase, not decrease, the frequency and success of attacks. (Eventually, AIs might be able to design completely impenetrable systems, but the cyber experts I’ve seen are sceptical of this.)
Bioterrorism is the one that really scares labs. The ability to engineer a super-virus, currently possessed only by a handful of countries and top labs, could become accessible to a large number of actors worldwide (budget bioterrorism, we might call it).
Mirror bacteria, which I discussed in slightly more depth in the last post, are about as offence-dominant as you can imagine – to the point where a few cells, dropped almost anywhere on Earth, may be very likely to cause the extinction of humanity (the science is not settled, but right now we’re scrambling for a reason this might not be the case). If AGI accelerates bioscience in the way the frontier labs all claim it will, we may become capable of building mirror bacteria within the decade, and sometime thereafter it may become almost easy.
Microrobotics are another obviously offence-dominant vector – think swarms of bee-sized drones with explosives flying into people’s heads, or mosquito-sized drones with toxins, deployed from larger drones which can cover distance. How on earth do you defend against that?
All scary stuff. Anyway, I bring all this up just to point out that even if you think takeover risks are a load of rubbish, rapid development of superhuman AI still certainly increases humanity’s annual chance of catastrophe – possibly to a really quite untenable place.
If we add these risks into the flowchart, it might look something like this (still simplified):
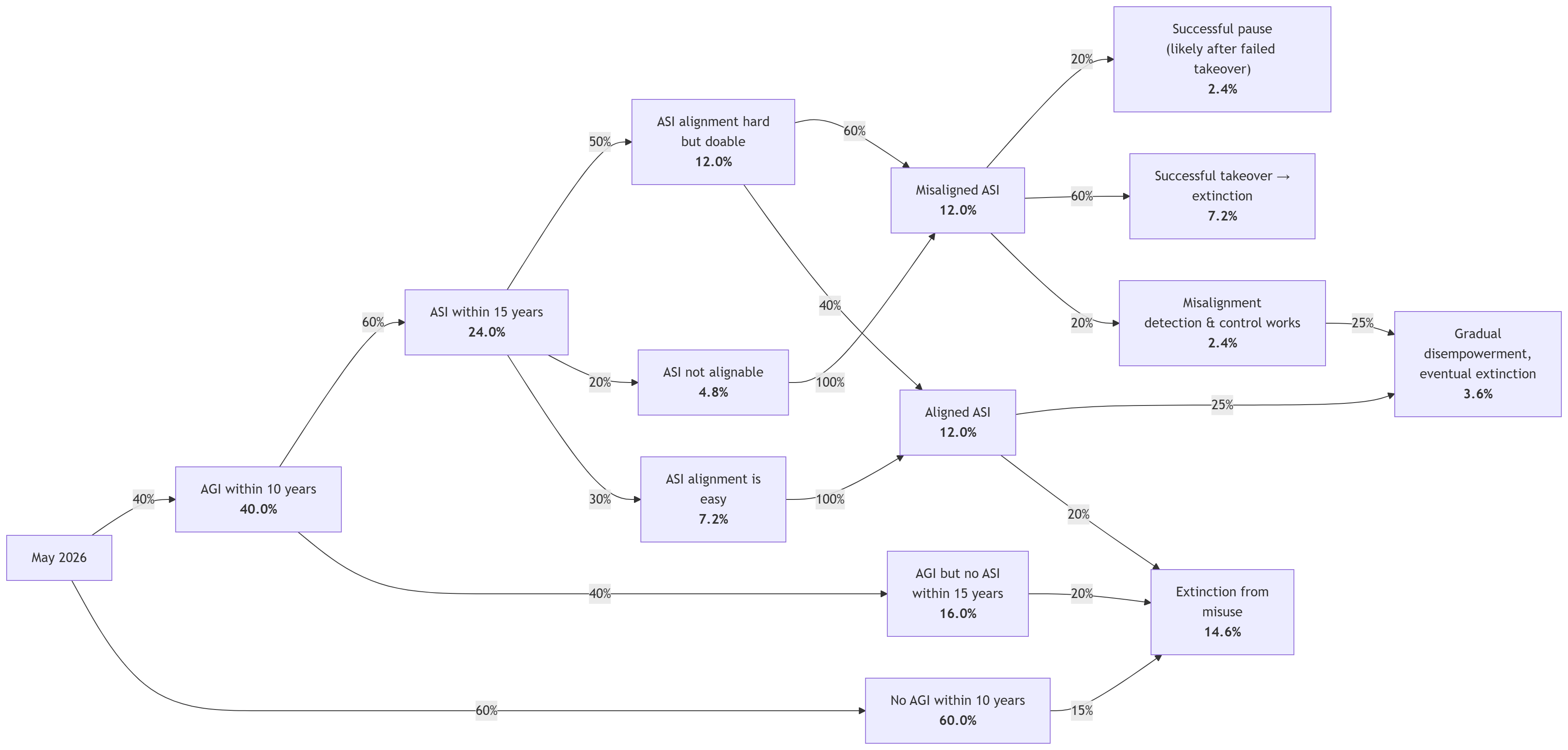
All in all, these numbers work out to roughly a one in four chance of extinction in the medium term. The probability is 55% if we get ASI, and 17% if we do not. That feels about right to me, though I’m constantly adjusting all the numbers in my head.
I would also note this excludes scenarios like most engineered pandemics which are unlikely to be extinction events but could still wipe out most humans.
What should we do about it?
The race to build ASI, both between US frontier labs, and between the US collectively and China, is a terrible idea. The most optimistic thing I can say about it is that I don’t think it will succeed, but my certainty is low. What should be done about this?
MIRI and Pause AI are pushing for an immediate, indefinite global pause to frontier LLM development until we can solve alignment. In the abstract, this might be the best outcome (a one-in-four chance of extinction motivates some extreme actions), but I don’t think it’s at all practical. The world does not and will not react to speculative, unproven threats by forfeiting great economic growth.
I’m more in favour of something like the Institute for Law & AI’s Radical Optionality, which argues governments should be willing to invest significant sums in building regulatory capabilities that improve information flow and allow them to act swiftly if ever needed, recognising that they may well not be; paired with Holden Karnofsky’s If-Then Commitments for AI Risk Reduction, which proposes labs and governments sign multilateral agreements to take certain mitigating actions upon certain “tripwires”. A tripwire is something like “AI can walk a moderately-resourced novice through producing a weapon of mass destruction with >10% chance of success” – then the mitigations would be (a) the model must be jailbreak-resistant against determined actors and (b) the weights must be secured against terrorist-level theft. If these can’t be met, discard the model.
The great thing about if-then treaties is that you can get governments to sign onto actions they think are absurd and would never usually consider doing (like banning unmonitored clusters of GPUs and striking dissidents), by conditioning them on events they think are just as absurd (like RSI suddenly producing a superintelligence). While you do expose the world to the risk you fail to detect the threat, or your conditions didn’t cast the right-shaped net, the upside is that you give governments an agreement they’re actually willing to sign. Oh, and you don’t deny yourself the economic and scientific prosperity that may come if we get robustly-aligned non-self-improving AGI.
This still leaves a lot of questions unanswered. What should the tripwires and greenlights be? What if China refuses to sign on – do we just race? How do we get labs’ information security w.r.t model weights and algorithmic secrets to a satisfactory level? (Do we need a Manhattan Project for AI?) How do we get anything productive from the current US administration?
I don’t have good answers to these. There’s still a lot of uncertainty as to what the eventual shape of the technology will be. But I think there are some obviously good things we should be trying to work towards, like:
Improving weight security. OpenAI and Google DeepMind are currently at RAND SL-2 (can likely thwart most professional opportunistic attempts with moderate effort), while Anthropic claim to be at SL-3 (can likely thwart cybercrime syndicates and insider threats). All of this is voluntary. This needs to change. OpenAI and GDM should not be allowed to still be at the “usually stops a lazy professional” level when they reach Mythos-level capabilities. And if the labs achieve their dreams of ASI, it had better be with SL-5, the level needed to defend against priority Chinese & Russian efforts, in place. Getting to this level will require a major effort, including the involvement of national intelligence agencies and the redesign of hardware – there must be a mandated plan to get there before ASI, including checklists they must satisfy at various points before moving capabilities forwards. This is an obviously sensible way to spend some of the head start the West has.
Deepen discussions with China. The last thing the CCP wants is a threat to their power, and they are already much more dialled in to the risk here than the USG – so I suspect they would be more amenable than many expect to some sensible if-then commitments (and an enforcement framework).
Export controls. The US already has 10x as much compute as China. Because Nvidia’s Blackwell and Rubin chips are massive sequential improvements, whereas Huawei’s 2026 and 2027 chips barely improve on 2025’s, this can expand towards 20x – but only if Nvidia is banned from selling Blackwell or Rubin to China. Unfortunately, Nvidia is actively lobbying against this, claiming it’s good for the US if Chinese models run on US chips. Hmm.
A red line on recursive self-improvement. At least nationally. Some people object that this means handing over the win to China, but in the worst case, we can always roll this back when the time comes. Again, trying to get robust alignment and governance in place before we summon the machine god seems like a good use of our head start. Others object that this is unenforceable – we’re going to need automated AI R&D for alignment purposes, so how do you distinguish RSI? It’s more of a “you know it when you see it” thing. Which is why we need…
Strong whistleblower protections. A lot of AI researchers are concerned about safety – they can be relied on, in principle, to flag dangerous behaviour, but they need good protections. These already exist in California following SB 53; they’re weaker at the federal level and in the UK.
Pre-deployment evaluations by national AI safety bodies. These already occur in the US and UK but are voluntary, and the AISIs lack the power to block deployment – even if, for example, a model is able to help a novice create bioweapons and is not robustly resistant to jailbreaking.
There are more. We’re fortunate to have good people working hard on all of these, but it isn’t yet clear that it’ll be enough.
Final Thoughts
I remain somewhat sceptical of takeover risk, and inclined to focus more on misuse risks – partly because I’m unconvinced that ASI is achievable with anything like the current setup, and partly because I think alignment of superintelligent language models is fairly likely to be tractable. In a way, we’re very fortunate that the most plausible near-term candidate for ASI comes in a form that natively embeds and understands human values - pre-2017, most AI researchers would not have guessed that, and I think a failure to update on this fact is probably responsible for most of the fatalism among doomers.

However, that is not to say I disregard the risk, particularly if recursive self-improvement works and is allowed to happen. My estimate of the takeover likelihood is still something like 7%, a large and uncomfortable number, rising to more like 30% if ASI comes about. And I’m conscious that my scepticism may stem more than I realise from a simulation heuristic.
At the end of the day, no one truly knows. Maybe AI is a normal technology, and all the doomsayers will look foolish in hindsight. Or maybe this really is February 2020. Anyone who claims certainty on this, in either direction, is a fool or a charlatan.
But it should not be controversial to say: when most of the experts in a field put the probability of extinction in the double digits, we should sit up and pay close attention.
I’m interested in working on these (and other) risks to humanity’s long-term future – likely via policy work or grantmaking, though I’m open to other paths too. If you know of any open roles where I may be a good fit, or have any proposals, please do get in touch.
Also, if you’re working on (or interested in working on) these problems yourself, please feel free to reach out – I’m always keen to hear more perspectives and to build out my network in these areas.
All the best,
Matt
LLMs are machines with one very specific goal - given a few hundred or thousand words, predict the word that comes next. On the inside, they consist of an enormous mass of numbers (“weights” or “parameters”) - upwards of a trillion these days - which collectively do that calculation. The cleverness of the design is that we can work out, knowing the actual next word, in which direction and how much to minutely adjust each one of those trillion numbers so that the machine’s guess would have been slightly more likely to be right (you have to make very small adjustments or everything goes to pot). This process is called gradient descent, as each step is akin to pushing a model “downhill” towards a less wrong guess.
The first step of training these to give you anything other than gobbledygook is called pretraining. You take a massive corpus of human-written text from the internet - like, 10 trillion words, and more if you can get your hands on it - and split it into chunks a few thousands words long. Then, for every single word, you run the preceding words in the chunk through the model, have it guess the word in question, then update the weights so it would be slightly more likely to get it right.
Despite the humble name and strange method, pretraining is regarded as the bit of training responsible for the vast majority of a model’s intelligence. It’s really quite surprising that pretraining works so well - how does predicting what some dipshit on Reddit is going to say help? But I guess eventually, you reach a point where you really can’t get any better by just mimicking human speech patterns and extrapolating simple patterns; you have to actually understand the world on some level to improve. You have to build a coherent internal representation of the human world’s concepts, and how they all relate, and how humans work and think. And indeed, with some clever maths we have looked inside the models and found evidence of just this - days of the week and months of the year are represented as circles/loops; colour is represented as a strange multidimensional manifold.
Next comes supervised fine-tuning (SFT). The first stage is essentially trying to get this intelligence to play the role of a helpful assistant, which actually tells you what it knows (unless that’s how to make a bomb) instead of acting like the average bastard on the internet. This is still done via gradient descent / next-word prediction, except now the “correct” next-word guess is the next word in whatever some human has written as an ideal helpful answer.
Next, instead of spitting out the first answer that comes to it, we teach the models to reason aloud - building upon its thoughts in real time, exploring different pathways until it’s satisfied with its final answer. A few human examples are sufficient to teach the models the structure here. Then we let it have a go itself, generating multiple attempts to reason its way to an answer on a harder question, and we reinforce the full chain-of-thought on whichever attempt gives the best output - we call this “reinforcement learning” (RL). Over time, it learns how to reason well. The development of this technique in 2024 led to OpenAI’s o1 and o3 models, which were step changes in intelligence over GPT-4.
Initially, we use a human judge or another AI to decide which answer is best. However, this technique is particularly powerful when paired with verifiable rewards such as code tests or maths problems - you can leave it whiling away at an incredibly difficult problem for hours, reinforcing its reasoning whenever it makes incremental progress such as passing another test. Originally, it was hoped that if we scale that up to millions of problems across a wide range of fields, it wouldn’t just learn how to do each well individually, but more fundamentally how to move through the world - how to write a good plan, how to know when to push on and when to try a new route; how to look at all the results from its failures and pull out the thread connecting them that unlocks the answer. This hasn’t really played out. Instead, models seem to be very good at learning each individual task, but weak at generalising to entirely new areas. But I’m getting ahead of myself - head back up to read the debate.
We do of course have to do a little more work for things particular to the AI’s situation as a chatbot that speaks to possibly hundreds of millions of people (e.g. relative political neutrality, non-sycophantism), and has a lot of potentially harmful knowledge (how to make weapons etc.).
Granted, you could certainly argue this apparent correlation only arises because humans are highly social creatures, which calls a wider range of more balanced goals, evolutionarily speaking. But the higher-level point is analogous to Yudkowsky’s own here - a simple reward function (reproductive fitness) was applied, and the end result was a creature with a wide range of well-balanced goals, none of which they chase to their logical extreme to the exclusion of all others (unless something goes badly wrong).
This was why I used my own ‘how it could play out’ story in my summary of the book - I think theirs has a few details like this that it doesn’t need to have, which weaken the story. No matter how much you caveat things as ‘just one potential path of many’, people will latch onto the weakest part of that story, and treat it as an assumption on which the whole argument rests. Their story did a disservice to the strength of their argument.
There are certainly a lot of people at all three frontier labs who care about this. Unfortunately that does not appear to include OpenAI’s leadership, or Google’s. Demis Hassabis does strike me as one of the good guys, but GDM have not covered themselves in glory as of late.
Superb as always Matt! I’m going to have to read this a few times, I wasn’t fully aware of the scale of the risks at play here. I get the sense that society is pricing this risk in the same category as nuclear weapons: not very unlikely in the long run but so bad that it’s not even worth thinking about. Hopefully anthropic (or similar) are smart enough to hire you in their safety department…